
“Be humble. Be hungry. And always be the hardest worker in the room.” - Dwayne Johnson
Projects
I am excited to showcase my projects, which are a tangible representation of my abilities and experience in my field. Through my projects, I have applied my skills and knowledge to real-world challenges and have demonstrated my ability to deliver results. By showcasing these projects, I hope to demonstrate my strengths, provide insight into my approach to problem-solving, and show how I have applied my skills and experience to projects that are relevant to the job or industry I am targeting. I look forward to sharing my projects with you and showing how my skills can add value to your organization.
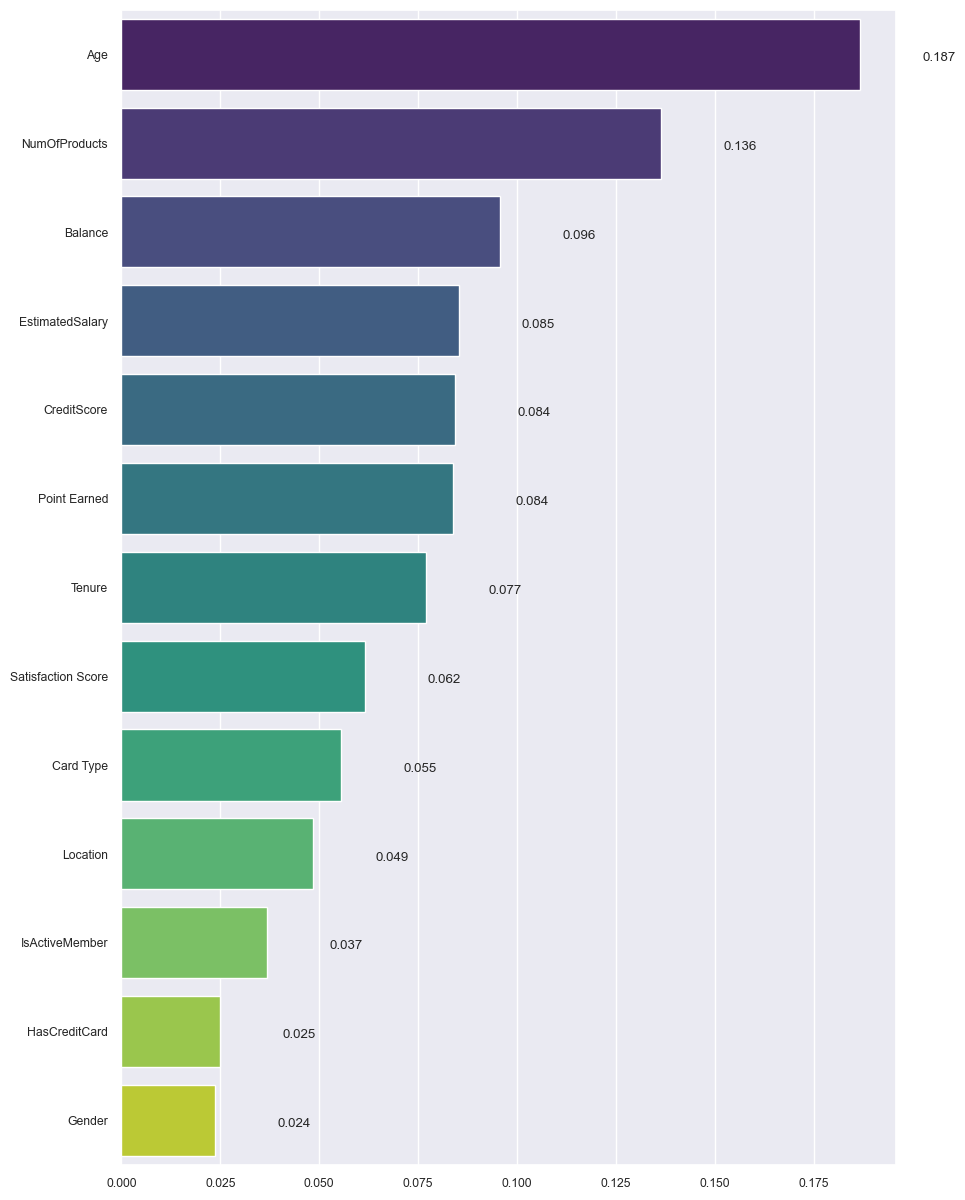
Analytics in Banking: An Examination of Customer Churn and Retention Rates
The report underscored the critical role of efficient customer complaint management in retaining customers, particularly within the banking sector. The insights derived from the analysis, which included potential regional variations in customer behavior and the importance of rigorous statistical analysis in deciphering customer data, could provide insights into targeting strategies to boost customer satisfaction and retention. Developing a logistic regression model capable of predicting customer complaints based on historical data emphasizes the potential of data-driven approaches in understanding and managing customer behavior. Despite limitations in knowledge regarding Machine Learning, the model delivered adequate performance, suggesting a similar or modified approach could be used for banks to address customer complaints, thereby enhancing satisfaction and retention proactively. Furthermore, future research should consider other predictive models and feature selection methods to improve prediction accuracy. Implementing such models in real-world scenarios can yield insights into their effectiveness in customer management strategies. The study pointed out avenues for further research, including an in-depth exploration of the factors influencing customer complaints and satisfaction scores and their impact on customer retention. This study reinforced the necessity for meticulous data exploration and preprocessing to achieve reliable predictive modeling results.
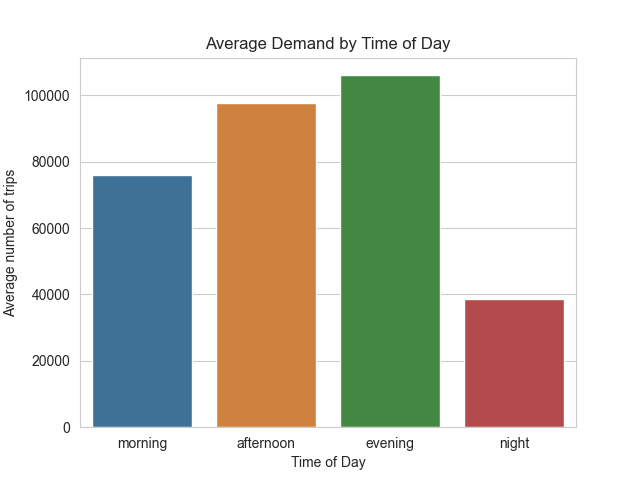
Analysis report - New York medallion (yellow) taxi's
In this report, both descriptive and predictive statistics are used to analyze New York yellow taxis' demand trends, peak periods, and revenue generation. Descriptive statistics are utilized to summarize and visualize the data, while predictive statistics are employed to develop prediction models for total fare amounts. The report also considers the impact of extreme weather events such as the largest blizzard on record to provide a more comprehensive understanding of the taxi industry's dynamics. Various prediction models, including linear regression, polynomial regression, and random forest regression, are tested to determine the best fit. Overall, the study emphasizes the importance of data cleaning and normalization to ensure accurate insights for stakeholders in the taxi industry.
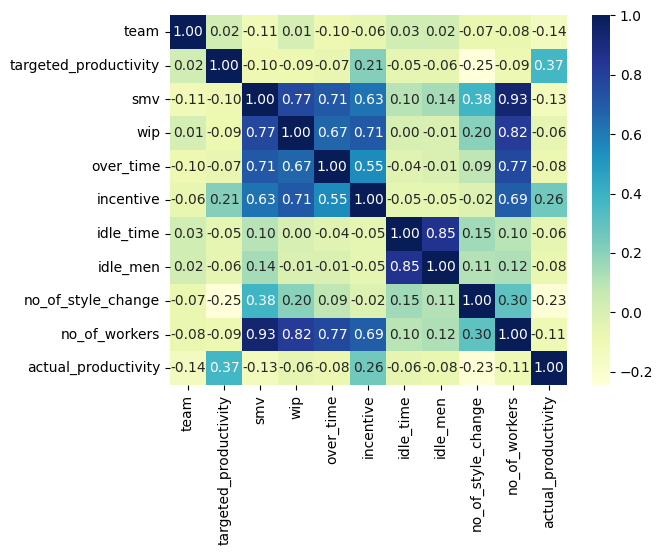
Analysis report - Garment factory productivity
The apparel industry is a significant contributor to the global economy, with developing countries such as Bangladesh playing a crucial role in its growth. To stay competitive, efficient resource allocation and production planning are vital. The use of tools like Standard Minute Value (SMV) and assembly line balancing techniques can increase productivity and reduce costs. Data analysis and visualization can provide insights into production performance, but addressing data quality issues such as outliers, missing values, and input errors is essential. Overtime and productivity indicators are valuable measures to evaluate departmental performance, and incorporating a day of rest, like Friday, can positively impact overall productivity. These findings can help apparel industries in developing countries identify areas for improvement and optimize their production processes. Proper planning and resource allocation are critical to optimizing production and increasing productivity. Seasonality, departmental dynamics, and style changes also impact productivity and should be considered when evaluating overall performance.
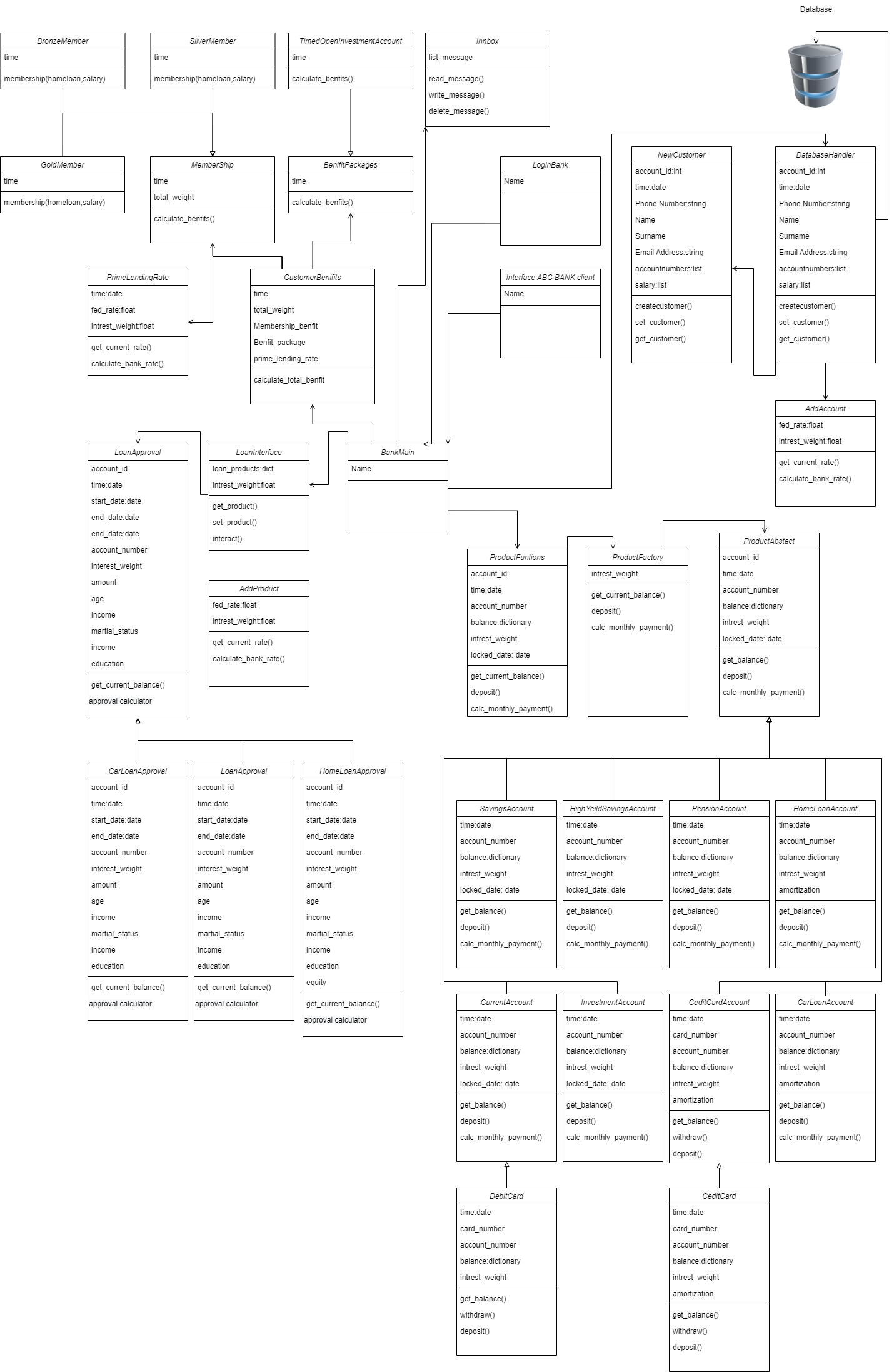
Bank prototype - OPP
This project is a prototype for a bank, designed to demonstrate to a team of developers how to implement the fundamentals of Object Oriented Programming. By using these principles, the project aims to ensure the longevity and flexibility of the product. Object Oriented Programming (OOP) is a programming paradigm that organizes software design around data, or objects, rather than functions and logic. The four fundamental principles of OOP are:
- Encapsulation
- Inheritance
- Polymorphism
- Abstraction
These principles are the building blocks of OOP, and they allow for the creation of more modular, flexible, and extensible software systems. By using these principles, developers can create software that is easier to maintain, modify, and expand.
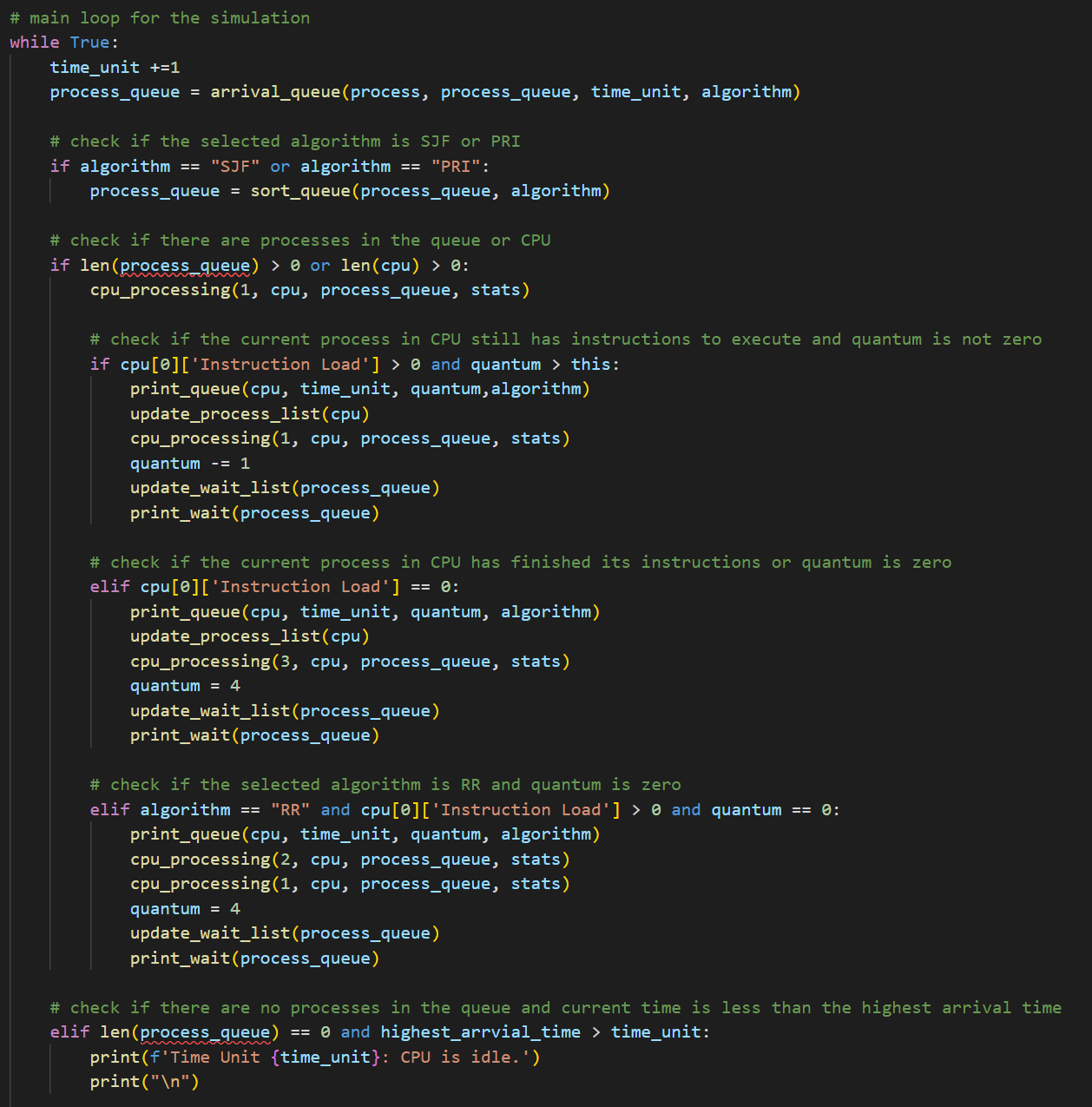
CPU sceduling algorithms
This program implements four different CPU scheduling algorithms:
- First-In-First-Out (FIFO) scheduling: This is the simplest scheduling algorithm, where the process that arrives first is executed first.
- Shortest Job First (SJF) scheduling: This algorithm executes the process with the shortest burst time first. It can reduce average waiting time, but it is difficult to estimate the burst time for each process.
- Priority scheduling: This algorithm assigns a priority to each process and executes the process with the highest priority first.
- Round Robin (RR) scheduling: This algorithm executes each process for a fixed amount of time (quantum), and then switches to the next process in the queue, until all processes have been executed. This ensures that no process monopolizes the CPU for too long, but can lead to increased overhead from frequent context switching.
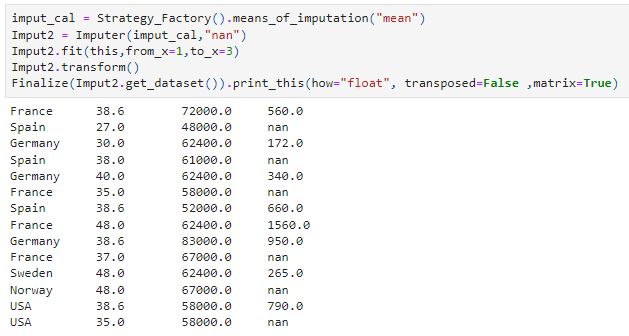
Customer Imputer - Strategy and factory pattern
This program is a custom built imputer, intergrating OOP princles and built to prepare a dataset for analysis.
- The program can tranpose data
- Convert string to int and vice versa
- Check for whatever any values need imputing default "NaN" and allows you to replace with whatever value needed
- It uses modular programming approach the allow user to switch out the functionality
- The program has the follow modules mean, mod and median for recalculating imputer values

Fake news detection - NLP(BERT)
This project explored using machine learning and natural language processing to detect fake news. Our group found that BERT was an ideal model, despite lower accuracy on unseen datasets. We believe that BERT could be a useful method for classifying the legitimacy of news articles. The project was challenging but provided valuable experience in data science. Further development of the model is necessary, and we aim to implement it as a web application that classifies news articles as "Real" or "Fake." The project gave us insight into fighting misinformation and expanded our knowledge of machine learning and AI. These principles are the building blocks of OOP, and they allow for the creation of more modular, flexible, and extensible software systems. By using these principles, developers can create software that is easier to maintain, modify, and expand.
Whatelse?
This is only a few projects that show case some of my abilities, I would recommend taking a look at the Skills section for a larger scope.